熔断
由于微服务间通过RPC来进行数据交换,所以我们可以做一个假设:在IO型服务中,假设服务A依赖服务B和服务C,而B服务和C服务有可能继续依赖其他的服务,继续下去会使得调用链路过长。如果在A的链路上某个或几个被调用的子服务不可用或延迟较高,则会导致调用A服务的请求被堵住,堵住的请求会消耗占用掉系统的线程、io等资源,当该类请求越来越多,占用的计算机资源越来越多的时候,会导致系统瓶颈出现,造成其他的请求同样不可用,最终导致业务系统崩溃,又称:雪崩效应。
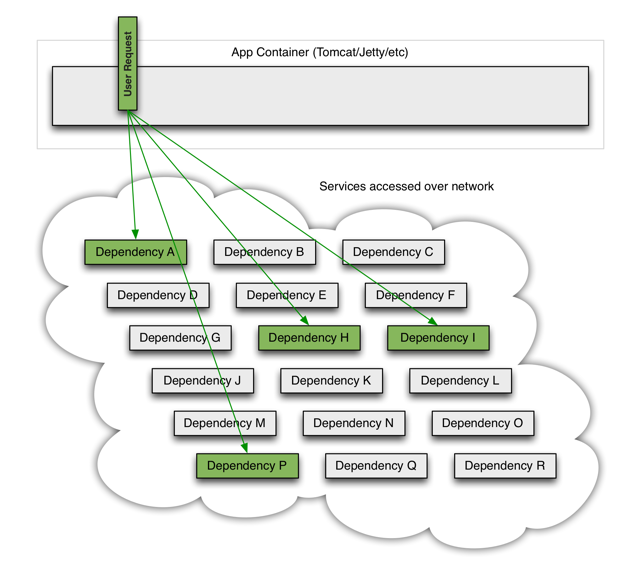
服务雪崩的原因
(1)某几个机器故障:例如机器的硬驱动引起的错误,或者一些特定的机器上出现一些的bug(如,内存中断或者死锁)。
(2)服务器负载发生变化:某些时候服务会因为用户行为造成请求无法及时处理从而导致雪崩。
(3)人为因素:比如代码中的路径在某个时候出现bug
在FeignClient中定义fallback,当服务出现问题时会通过指定的fallback快速返回。
/**
* @author liuzhibin
* Date: 2019/10/27
*/
@FeignClient(value = "ofa-admin",fallback = UserInfoFallBack.class)
public interface UserInfoFeign {
/**
* 根据token获取用户信息
*
* @param token
* @return
*/
@GetMapping("/admin/ofaUser/userInfo")
RestData getUserInfo(@RequestParam(value = "token") String token);
}
fallback:
@Component
public class UserInfoFallBack implements UserInfoFeign {
@Override
public RestData getUserInfo(String token) {
return new RestData(-1, "获取用户信息失败");
}
}
这样当服务的接口出现问题时,会进行熔断并返回fallback信息,避免了雪崩现象。
{
"code": -1,
"data":null,
"desc": "获取用户信息失败"
}